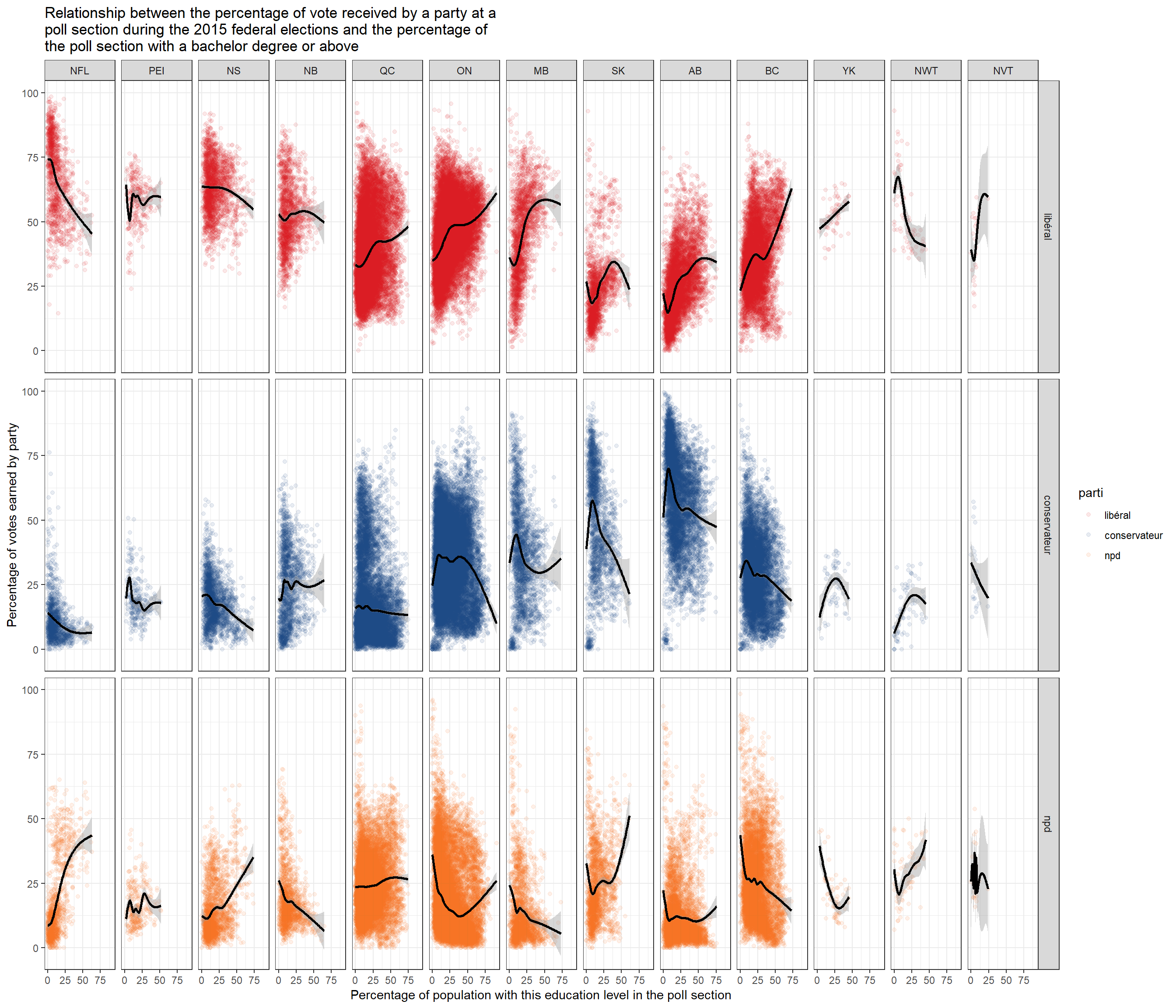
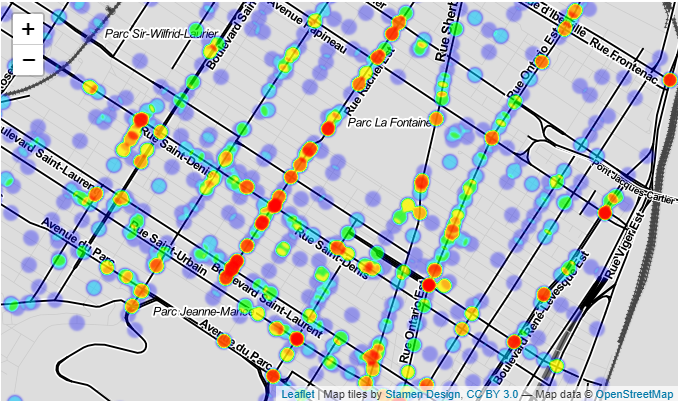
A recent by Arthur Charpentier (@freakonometrics) has inspired me to finally give Jens von Bergmann’s (@vb_jens) dotdensity package a run.
I will come back to this code for some examples of how to use dotdensity but also for rmapzen road and water tiles.
At first glance, it appears that the immigrants in Montréal from France, Italy, China and Lebanon won’t run into each other very often. Immigrants from Haiti and Algeria and Morocco and both more likely to be found in the North of the island.